
How Do You Pronounce “GIF”?
The Project
For my third project at Metis, my goal was to build a model to predict how people pronounced GIF (i.e., with a hard “g”, like “gift”; with a soft “g”, like “jiff”; or some other way) using responses from the 2017 StackOverflow Developers Survey. The survey consisted of questions about Developer attitudes, job-seeking and compensation, education and professional development, software practices, hardware and tools, Stack Overflow attitudes.
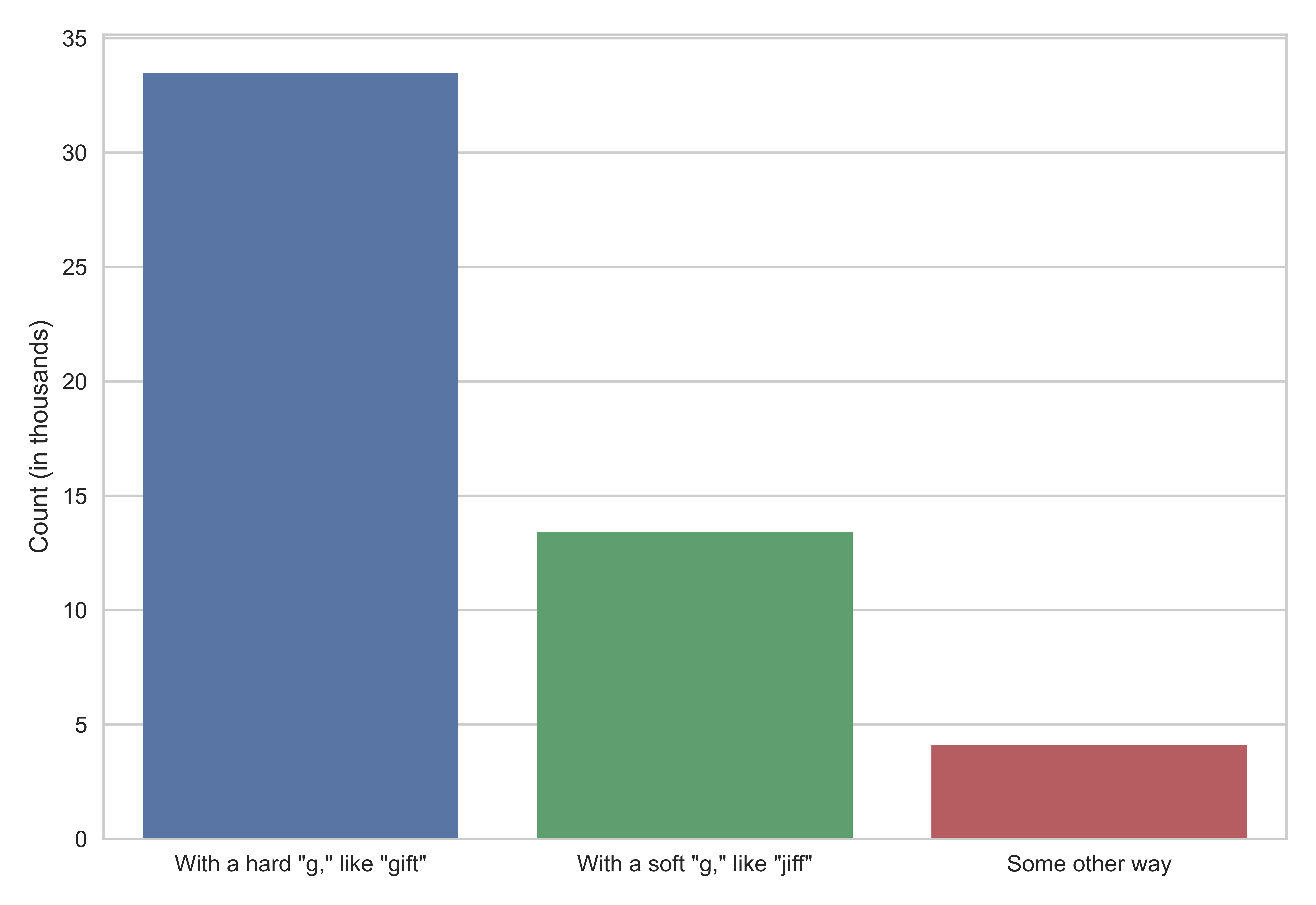
The majority of the respondents pronounced GIF with a hard “g”.
Feature Engineering
Almost all of the survey questions had multiple choice responses, resulting in categorical features. In order to fit different types of classification models using scikit-learn, at a minimum all the responses need to be converted into dummy variables. As a first pass, I did just this: I converted all features into dummy variables and ran a random forest model. However, the model’s f1 score was lower than the base model (i.e., predicting that everyone pronounced GIF with a hard “g” since it is the largest class), indicating poor performance.
To improve the model, I tried feature engineering. When possible, I converted categorical responses into continuous features (i.e., features involving years and time). I also examined each survey question and response and I thought of ways to generate new features that would be associated with the target variable. For instance, respondent’s country of origin was coded as native and non-native English-speaking countries.
My process consisted of doing some feature engineering, and then model fitting to assess the change in model metrics and feature importance. Both these steps were iterated over multiple times.
Classification Models
For this project, I fit a number of different classification models (e.g., logistic regression (with regularization), K Nearest Neighbors, and Random Forest) and tried to tune their hyperparameters. Since I had trouble with using GridSearchCV on my AWS instance, I used for loops to try out different parameters and find the best ones.
It was a challenge to find predict the pronunciation of GIF using the Developers Survey. The best performing model was the random forest (based on f1 score). It had a small improvement over the base model. However, this model also had a slightly lower accuracy score and tended to over predict the pronunciation of GIF with a hard “g”.
| Model | f1 Score | Accuracy Score |
|---|---|---|
| Base | 0.39 | 0.66 |
| Random Forest | 0.45 | 0.64 |
Important Features
I was also interested to see if various features were associated with the pronunciation of GIF. I examined the features identified as important from the random forest model using Bokeh for interactive plots. Here are a couple of interesting finds.
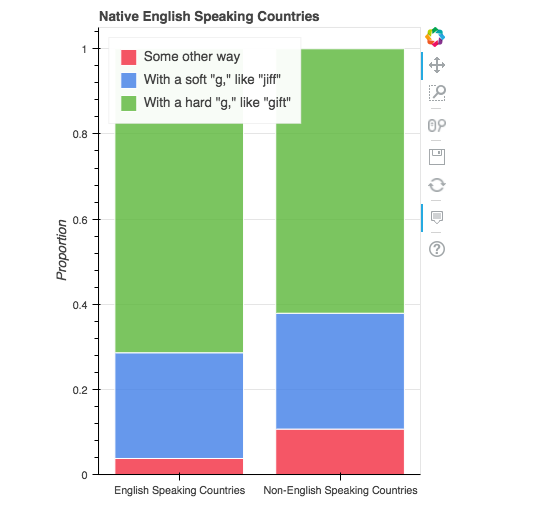
Non-native English speakers were more likely to pronounce GIF as some other way than native English speakers. They were also less likely to pronounce GIF with a hard “g”.
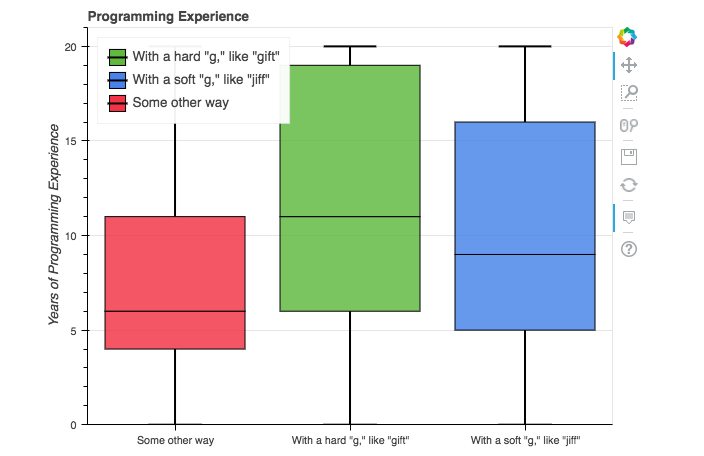
People who pronounce GIF with a hard “g” tended to have more programming experience than the other classes, while those who use some other pronunciation tended to have less programming experience.
Reflections
Although there are some features that were associated with how people pronounce GIF, it is difficult to build a good prediction model using data from the 2017 StackOverflow Developer Survey. The data used in this project probably doesn’t capture information that is necessary for predicting how people pronounce GIF, highlighting the importance of data when building predictive models.
All is not lost! The methods used for this project would be applicable to similar projects that aims to predict a behavior using survey responses. With every data science project I complete at Metis, I have learned a lot. Not only have I gained experience with feature engineering and running classification models using scikit-learn, but I also used an AWS instance, to run the data analyses, and Bokeh, to create interactive plots, for the first time. In addition, I really enjoyed the problem solving aspect of feature engineering and thinking critically about the data.